


关于微服务架构中的服务发现,在《要学习微服务的服务发现?先来了解一些科普知识吧》一文中有全面的介绍。
微服务架构中服务实例的IP是动态分配。同时,还面临着服务的增减、故障、升级等变化。这种情况,对于客户端程序来说,就需要使用更精确的服务发现机制。为了解决这个问题,于是像etcd、Consul、Apache Zookeeper、Nacos等服务注册中间件便应运而生。
Nacos简介
Nacos的功能官方用一句话来进行了说明:“一个更易于构建云原生应用的动态服务发现、配置管理和服务管理平台。”
Nacos 支持几乎所有主流类型的“服务”的发现、配置和管理:
Kubernetes Service
gRPC & Dubbo RPC Service
Spring Cloud RESTful Service
官网给出了Nacos的4个核心特性:服务发现和服务健康监测、动态配置服务、动态DNS服务、服务及其元数据管理。本文主要来讲服务发现功能。
Nacos的Server与Client
Nacos注册中心分为Server与Client,Nacos提供SDK和openApi,如果没有SDK也可以根据openApi手动写服务注册与发现和配置拉取的逻辑。
Server采用Java编写,基于Spring Boot框架,为Client提供注册发现服务与配置服务。
Client支持包含了目前已知的Nacos多语言客户端及Spring生态的相关客户端。Client与微服务嵌套在一起。
Nacos的DNS实现依赖了CoreDNS,其项目为nacos-coredns-plugin。该插件提供了基于CoreDNS的DNS-F客户端,开发语言为go。
Nacos注册中的交互流程
作为注册中心的功能来说,Nacos提供的功能与其他主流框架很类似,基本都是围绕服务实例注册、实例健康检查、服务实例获取这三个核心来实现的。
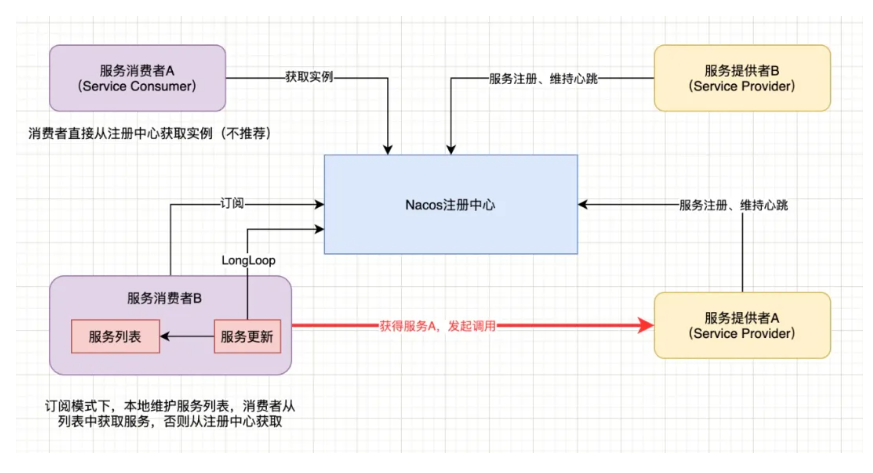
以Java版本的Nacos客户端为例,服务注册基本流程:
服务实例启动将自身注册到Nacos注册中心,随后维持与注册中心的心跳;
心跳维持策略为每5秒向Nacos Server发送一次心跳,并携带实例信息(服务名、实例IP、端口等);
Nacos Server也会向Client主动发起健康检查,支持TCP/Http;
15秒内无心跳且健康检查失败则认为实例不健康,如果30秒内健康检查失败则剔除实例;
服务消费者通过注册中心获取实例,并发起调用;
其中服务发现支持两种场景:第一,服务消费者直接向注册中心发送获取某服务实例的请求,注册中心返回所有可用实例,但一般不推荐此种方式;第二、服务消费者向注册中心订阅某服务,并提交一个监听器,当注册中心中服务发生变化时,监听器会收到通知,消费者更新本地服务实例列表,以保证所有的服务均可用。
Nacos数据模型
关于数据模型,官网描述道:Nacos数据模型的Key由三元组唯一确定,Namespace默认是空串,公共命名空间(public),分组默认是DEFAULT_GROUP。
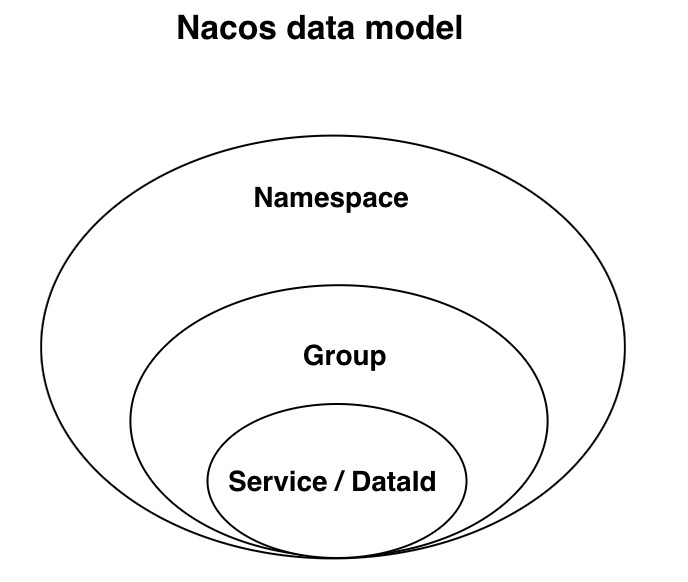
整个层级的包含关系为Namespace包含多个Group、Group可包含多个Service、Service可包含多个Cluster、Cluster中包含Instance集合。
其中,实例又分为临时实例和持久化实例。它们的区别关键是健康检查的方式。临时实例使用客户端上报模式,而持久化实例使用服务端反向探测模式。
临时实例需要能够自动摘除不健康实例,而且无需持久化存储实例。持久化实例使用服务端探测的健康检查方式,因为客户端不会上报心跳,自然就不能去自动摘除下线的实例。
临时实例和永久实例
临时实例
临时实例在注册到注册中心之后仅仅只保存在服务端内部一个缓存中,不会持久化到磁盘
这个服务端内部的缓存在注册中心届一般被称为服务注册表
当服务实例出现异常或者下线之后,就会把这个服务实例从服务注册表中剔除
永久实例
永久服务实例不仅仅会存在服务注册表中,同时也会被持久化到磁盘文件中
当服务实例出现异常或者下线,Nacos 只会将服务实例的健康状态设置为不健康,并不会对将其从服务注册表中剔除
所以这个服务实例的信息你还是可以从注册中心看到,只不过处于不健康状态
为什么 Nacos 要将服务实例分为临时实例和永久实例?
主要还是因为应用场景不同
临时实例就比较适合于业务服务,服务下线之后可以不需要在注册中心中查看到
永久实例就比较适合需要运维的服务,这种服务几乎是永久存在的,比如说 MySQL、Redis 等等。对于这些服务,我们需要一直看到服务实例的状态,即使出现异常,也需要能够查看时实的状态
服务注册
所谓的服务注册,就是通过注册中心提供的客户端 SDK(或者是控制台)将服务本身的一些元信息,比如 ip、端口等信息发送到注册中心服务端。服务端在接收到服务之后,会将服务的信息保存到前面提到的服务注册表中。
在 Nacos 在 1.x 版本的时候,服务注册是通过 Http 接口实现的
但是在 2.x 版本的实现就比较复杂了
通信协议的改变
2.x 版本相比于 1.x 版本最主要的升级就是客户端和服务端通信协议的改变,由 1.x 版本的 Http 改成了 2.x 版本 gRPC
gRPC 是谷歌公司开发的一个高性能、开源和通用的 RPC 框架,Java 版本的实现底层也是基于 Netty 来的
之所以改成了 gRPC,主要是因为 Http 请求会频繁创建和销毁连接,白白浪费资源
所以在 2.x 版本之后,为了提升性能,就将通信协议改成了 gRPC
根据官网显示,整体的效果还是很明显,相比于 1.x 版本,注册性能总体提升至少 2 倍
虽然通信方式改成了 gRPC,但是 2.x 版本服务端依然保留了 Http 注册的接口,所以用 1.x 的 Nacos SDK 依然可以注册到 2.x 版本的服务端
具体的实现

Nacos 客户端在启动的时候,会通过 gRPC 跟服务端建立长连接
这个连接会一直存在,之后客户端与服务端所有的通信都是基于这个长连接来的
当客户端发起注册的时候,就会通过这个长连接,将服务实例的信息发送给服务端
服务端拿到服务实例,跟 1.x 一样,也会存到服务注册表
除了注册之外,当注册的是临时实例时,2.x 还会将服务实例信息存储到客户端中的一个缓存中,供 Redo 操作
所谓的 Redo 操作,其实就是一个补偿机制,本质是个定时任务,默认每 3s 执行一次
这个定时任务作用是,当客户端与服务端重新建立连接时(因为一些异常原因导致连接断开)
那么之前注册的服务实例肯定还要继续注册服务端(断开连接服务实例就会被剔除服务注册表)
所以这个 Redo 操作一个很重要的作用就是重连之后的重新注册的作用
除了注册之外,比如服务订阅之类的操作也需要 Redo 操作,当连接重新建立,之前客户端的操作都需要 Redo 一下
心跳机制
心跳机制,也可以被称为保活机制,它的作用就是服务实例告诉注册中心我这个服务实例还活着
在正常情况下,服务关闭了,那么服务会主动向 Nacos 服务端发送一个服务下线的请求
Nacos 服务端在接收到请求之后,会将这个服务实例从服务注册表中剔除
但是对于异常情况下,比如出现网络问题,可能导致这个注册的服务实例无法提供服务,处于不可用状态,也就是不健康
而此时在没有任何机制的情况下,服务端是无法知道这个服务处于不可用状态
所以为了避免这种情况,一些注册中心,就比如 Nacos、Eureka,就会用心跳机制来判断这个服务实例是否能正常
心跳机制在 1.x 和 2.x 版本的实现也是不一样的
1.x心跳实现
在 1.x 中,心跳机制实现是通过客户端和服务端各存在的一个定时任务来完成的
在服务注册时,发现是临时实例,客户端会开启一个 5s 执行一次的定时任务
这个定时任务会构建一个 Http 请求,携带这个服务实例的信息,然后发送到服务端

在 Nacos 服务端也会开启一个定时任务,默认也是 5s 执行一次,去检查这些服务实例最后一次心跳的时间,也就是客户端最后一次发送 Http 请求的时间
当最后一次心跳时间超过 15s,但没有超过 30s,会把这服务实例标记成不健康
当最后一次心跳超过 30s,直接把服务从服务注册表中剔除
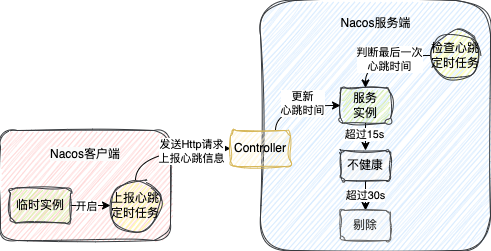
1.x 版本的心跳机制,本质就是两个定时任务
服务在处理心跳的时候,发现心跳携带这个服务实例的信息在注册表中没有,此时就会添加到服务注册表
2.x心跳实现
在 2.x 版本之后,由于通信协议改成了 gRPC,客户端与服务端保持长连接,所以 2.x 版本之后它是利用这个 gRPC 长连接本身的心跳来保活
一旦这个连接断开,服务端就会认为这个连接注册的服务实例不可用,之后就会将这个服务实例从服务注册表中提出剔除
除了连接本身的心跳之外,Nacos 还有服务端的一个主动检测机制
Nacos 服务端也会启动一个定时任务,默认每隔 3s 执行一次
这个任务会去检查超过 20s 没有发送请求数据的连接
一旦发现有连接已经超过 20s 没发送请求,那么就会向这个连接对应的客户端发送一个请求
如果请求不通或者响应失败,此时服务端也会认为与客户端的这个连接异常,从而将这个客户端注册的服务实例从服务注册表中剔除
所以对于 2.x 版本,主要是两种机制来进行保活:
连接本身的心跳机制,断开就直接剔除服务实例
Nacos 主动检查机制,服务端会对 20s 没有发送数据的连接进行检查,出现异常时也会主动断开连接,剔除服务实例
小结
总结
心跳机制仅仅针对临时实例而言
1.x 心跳机制是通过客户端和服务端两个定时任务来完成的,客户端定时上报心跳信息,服务端定时检查心跳时间,超过 15s 标记不健康,超过 30s 直接剔除
1.x 心跳机制还有类似 2.x 的 Redo 作用,服务端发现心跳的服务信息不存在会,会将服务信息添加到注册表,相当于重新注册了
2.x 是基于 gRPC 长连接本身的心跳机制和服务端的定时检查机制来的,出现异常直接剔除
健康检查
前面说了,心跳机制仅仅是临时实例用来保护的机制
而对于永久实例来说,一般来说无法主动上报心跳
就比如说 MySQL 实例,肯定是不会主动上报心跳到 Nacos 的,所以这就导致无法通过心跳机制来保活
所以针对永久实例的情况,Nacos 通过一种叫健康检查的机制去判断服务实例是否活着
健康检查跟心跳机制刚好相反,心跳机制是服务实例向服务端发送请求
而所谓的健康检查就是服务端主动向服务实例发送请求,去探测服务实例是否活着

健康检查机制在 1.x 和 2.x 的实现机制是一样的
Nacos 服务端在会去创建一个健康检查任务,这个任务每次执行时间间隔会在 2000~7000 毫秒之间
当任务触发的时候,会根据设置的健康检查的方式执行不同的逻辑,目前主要有以下三种方式:
TCP
HTTP
MySQL
TCP 的方式就是根据服务实例的 ip 和端口去判断是否能连接成功,如果连接成功,就认为健康,反之就任务不健康
HTTP 的方式就是向服务实例的 ip 和端口发送一个 Http 请求,请求路径是需要设置的,如果能正常请求,说明实例健康,反之就不健康
默认情况下,都是通过 TCP 的方式来探测服务实例是否还活着
服务发现
所谓的服务发现就是指当有服务实例注册成功之后,其它服务可以发现这些服务实例
Nacos 提供了两种发现方式:
主动查询
服务订阅
主动查询 就是指客户端主动向服务端查询需要关注的服务实例,也就是拉(pull)的模式。
服务订阅 就是指客户端向服务端发送一个订阅服务的请求,当被订阅的服务有信息变动就会主动将服务实例的信息推送给订阅的客户端,本质就是推(push)模式。
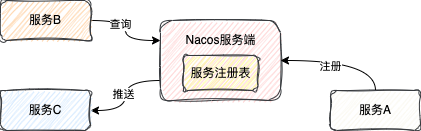
在我们平时使用时,一般来说都是选择使用订阅的方式,这样一旦有服务实例数据的变动,客户端能够第一时间感知。
服务查询其实两者实现都很简单
1.x 整体就是发送 Http 请求去查询服务实例,2.x 只不过是将 Http 请求换成了 gRPC 的请求
服务端对于查询的处理过程都是一样的,从服务注册表中查出符合查询条件的服务实例进行返回
不过对于服务订阅,两者的机制就稍微复杂一点
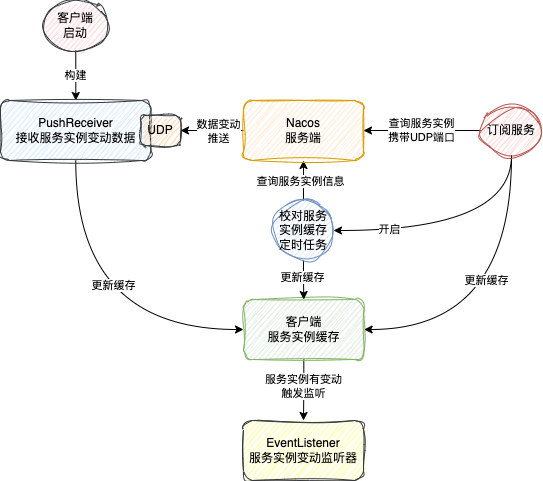
在 Nacos 客户端,不论是 1.x 还是 2.x 都是通过 SDK 中的NamingService#subscribe方法来发起订阅的
当有服务实例数据变动的时,客户端就会回调EventListener,就可以拿到最新的服务实例数据了
虽然 1.x 还是 2.x 都是同样的方法,但是具体的实现逻辑是不一样的
1.x 版本的服务订阅的实现
2.x 版本的服务订阅功能的实现
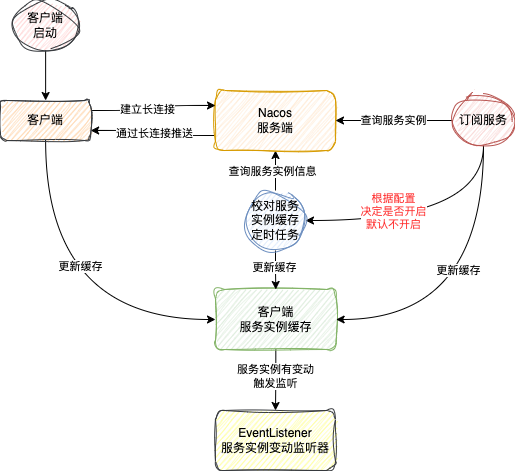
在 1.x 版本的时候,任何服务都是可以被订阅的
但是在 2.x 版本中,只支持订阅临时服务,对于永久服务,已经不支持订阅了
1.x 和 2.x 客户端都有服务实例的缓存,也有定时对比机制,只不过 1.x 会自动开启;2.x 提供了一个开关,可以手动选择是否开启,默认不开启
集群间数据是如何同步的?CP 还是 AP?
Nacos 的数据模型是什么样的?
评论区